Data Collection Strategies to Drive Better Machine Learning Results
.png)
AI Data Collection Company begins with information. In any case, for this information to work, a few cycles should be completed. One of them is information assortment.
Basically, information assortment is the method involved with social occasion information pertinent to your simulated intelligence venture's objectives and goals. You ultimately get a dataset, which is basically your assortment of information, all set to be prepared and taken care of into a ML model. How hard could it at any point be?
As straightforward as it might appear from the outset, information assortment is truth be told the first and most crucial stage in the AI pipeline. It's essential for the complicated information handling stage inside a ML lifecycle. From this comes another significant point: information assortment straightforwardly influences the presentation of a ML model and the eventual outcomes. However, we should discuss everything all together.
Here is a point by point AI system, which shows the job of information assortment in the whole pipeline:
- Characterizing the task's objective
- ML issue proclamation
- Information handling (information assortment, information preprocessing, highlight designing)
- Model turn of events (preparing, tuning, assessment)
- Model arrangement (induction, forecast)
- Following the presentation of a ML model
Inappropriate information assortment is a huge boundary to productive AI. Thus, information assortment has as of late turned into a highly controversial issue in the worldwide tech local area for basically two reasons. The main explanation is that as AI is utilized more regularly, we are seeing new applications that might not have an adequate number of marked information. Second, profound learning calculations, in contrast to customary ML strategies, consequently produce highlights, saving money on highlight designing costs however possibly requiring more commented on information.
Nonetheless, the exactness of the expectations or suggestions delivered by ML frameworks relies upon the preparation information. However, a few issues could happen during ML information assortment that influence the exactness rate:
- Inclination. Since people who develop ML models are inclined to predisposition, information inclination is extremely challenging to forestall and dispense with.
- Wrong information. The accumulated information probably won't be pertinent to the ML issue articulation.
- Missing information. For certain classes of expectation, missing information can address void qualities in segments or missing pictures.
- Information unevenness. A gamble of underrepresentation in the model exists for a gatherings or classes in the information because of an unreasonably enormous or low number of relating tests.
Finding out about information assortment instruments and techniques is significant to understanding how to make a dataset and acquiring a more profound information on AI generally. Having quality information available ensures a good outcome with any undertaking in ML.
All things considered, we should get directly to information assortment!
Information Assortment: Cycles, Strategies, and Instruments

Right now, it's a good idea to review an old fashioned rule in ML: trash in, trash out, and that implies a machine is said to realize precisely exact thing it's educated. All the more explicitly, taking care of your model with poor and bad quality information won't create any nice outcomes, paying little mind to how refined your model is, the means by which gifted an information researcher is, or how much cash you've spent on an undertaking.
Computer based intelligence frameworks need information similarly however much living things need air to work appropriately, which is the reason monstrous volumes of both organized and unstructured information empowered a new blast in the viable utilization of AI. On account of ML, we presently have phenomenal proposal frameworks, prescient examination, design acknowledgment innovation, sound to-message record, and, surprisingly, self-driving vehicles.
Unstructured text information is utilized by 68% of computer based intelligence engineers, making it the most well-known kind of information. With 59% use, plain information is the second most normal sort of information.
The critical activities in the information assortment stage include:
- Name: Marked information is the crude information that was handled by adding at least one significant labels so a model can gain from it. It will take a work to mark it on the off chance that such data is missing (physically or naturally).
- Ingest and Total: Consolidating and joining information from numerous information sources is essential for information assortment in simulated intelligence.
To comprehend the interaction and the fundamental thought behind information assortment, one ought to likewise sort out the essentials of information securing, information explanation, and the improvement strategies for the current information and ML models. Likewise, the mix of ML and information the board for information assortment comprises a lot greater pattern of enormous information and simulated intelligence combination, setting out new open doors for information driven organizations that figure out how to dominate this interaction.
We've arranged a short outline of the main cycles, which are all important for information assortment in AI. Continue to peruse to figure out more about what is an information assortment technique and a few valuable information assortment devices (gave in sections):
Stage 1: Information Securing
Considering that a few organizations have been gathering their information for a really long time, there ought not be all any issues for them with respect to information assortment for AI. Notwithstanding, on the off chance that you need information, don't surrender. You can basically utilize a reference dataset that you can see as online to finish your simulated intelligence project. We have a whole article covering the most famous sources where you can find online ML datasets.
You can find new information and offer it by utilizing three strategies: cooperative investigation (DataHub), web (Google Combination Tables, CKAN, Quandl, and DataMarket), and cooperative and web (Kaggle). Notwithstanding these stages, there are frameworks intended for information recovery, like information lakes (Google Information Search) and web (WebTables).
Stage 2: Information Expansion
Start the most common way of gathering your own information in the fitting shape and configuration while assessing the recovered dataset. On the off chance that that suits your necessities, it very well may be in a similar organization as the reference dataset; in any case, in the event that the thing that matters is huge, it very well may be in an alternate configuration.
However, on the off chance that you need more example information, you want information expansion. Regardless of whether we couldn't find a dataset that totally paired every one of our models yet at the same time had a few fundamental information, we can in any case utilize it. Be that as it may, we should utilize increase strategies on our dataset to grow the sum and size of tests.
Adding outer information to existing datasets is one more strategy for information assortment, which makes your dataset more extravagant. Methods applied for information expansion incorporate determining inert semantics, element increase, and information coordination.
Stage 3: Information Age
Another strategy is to make an AI dataset physically or naturally in the event that there aren't any generally that can utilized for train. Publicly supporting (Amazon Mechanical Turk, a simulated intelligence information assortment organization) is the go-to technique for manual assortment of the essential bits of information that together structure the created dataset.
Assuming you've been managing information assortment of pictures, you're really great for the present, however imagine a scenario in which you have tables with information yet insufficient information. How might we get a greater amount of it? In this specific case, we can utilize manufactured information generators. It's an elective strategy to consequently make manufactured datasets (utilizing GANs). Be that as it may, to utilize them accurately, we should fathom the standards and regulations overseeing the arrangement of ML datasets.
We can now start the genuine AI, since we have every one of the necessary information.
The Information Has Been Gathered, What's Straightaway? Making a Dataset!
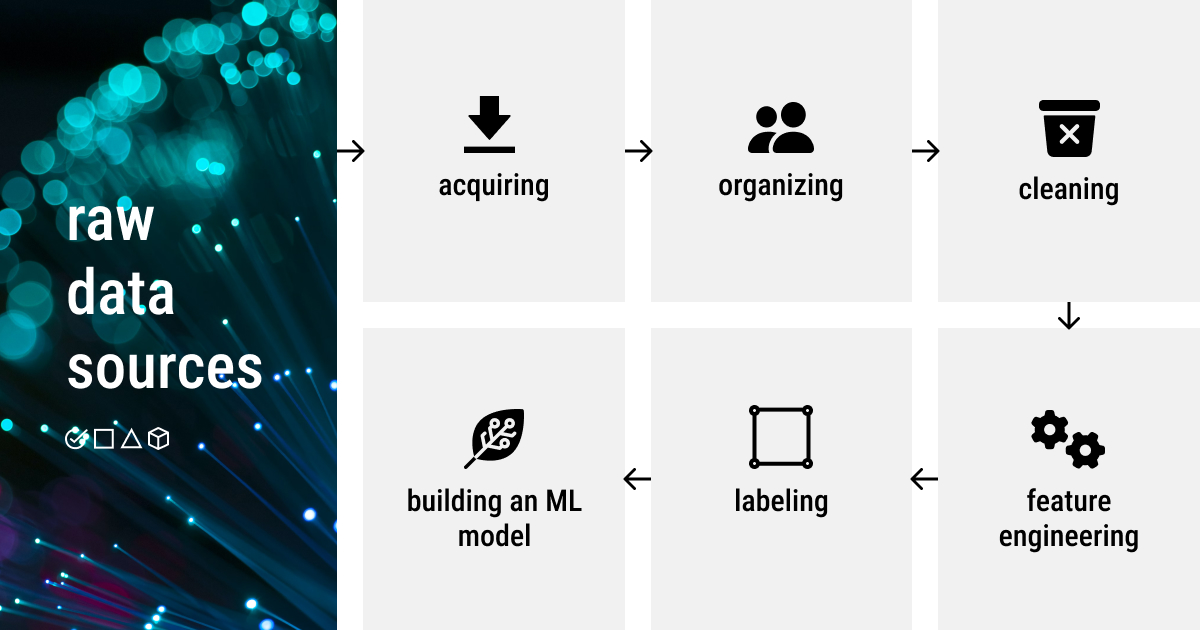
Since we have every one of the fundamental information, we can begin doing the genuine AI, which is separating significant information from information and making it coherent for a ML model. Getting ready information for AI is further developing the current information that you need to guarantee that the model will create the most reliable and dependable outcomes.
The accompanying advances that we'll look at carry us nearer to the most common way of making a dataset (i.e., characterization dataset) for an AI model and setting it up for additional preparation, assessment, and testing.
Stage 4: Information Preprocessing
Regardless of where you got the dataset from, it should be tidied up, filled, refined, and by and large ensured you can really receive significant data in return before you use it to foster a ML framework.
It's important to preprocess the information after it has been gathered to prepare it for a ML task. Information preprocessing is a wide term that envelops various errands, from information organizing to highlight creation. We should investigate every one of the cycles!
Arranging
Tragically, we don't reside ideally, where the information is as of now cleaned and designed before an information researcher gathers it. In a genuine case situation, the information is assembled from different sources and, in this manner, should be designed. While working with text information, the end dataset is often a XLS/CSV record, a sent out calculation sheet from the data set, or both. Assuming that you have picture information to preprocess, you should coordinate it into lists to simplify everything for ML structures.
Cleaning
When the information is organized, it very well may be effortlessly taken care of into the model for additional preparation. In any case, designed information doesn't mean it's liberated from blunders and exceptions (otherwise known as irregularities) and that all information is appropriately organized. The planning of information before further preprocessing matters since the right, exact information firmly affects the result. To this end information cleaning (or purifying) is a vital movement. Information that has been added or sorted erroneously is taken out utilizing manual and robotized information cleaning processes, which additionally assists in managing missing information, copies, underlying mistakes, and exceptions.
Include Designing
This one is a seriously unpredictable and relentless interaction, which comprises of dealing with all out information, highlight scaling, dimensionality decrease, and component determination. Moreover, the key element designing techniques applied at this stage incorporate channel strategies, covering strategies, installed techniques, and component creation. This fundamentally involves the improvement of extra highlights that would upgrade the model more than those that as of now exist. It requires various cycles, including discretization,



Comments
Post a Comment